A Real, Annotated CLAUDE.md: The Config I Actually Use With Claude Code
A line-by-line look at a real, tuned CLAUDE.md for Claude Code: what each rule does, why it earns its place, and how to stop Claude ignoring your config.

On this page
Almost every "CLAUDE.md best practices" article gives you a list of principles and a blank file to start from. This is the opposite of that. Below is a real, tuned CLAUDE.md I actually run, annotated line by line: what each rule does, why it earned its place, and what failure it stops. If you have searched for a CLAUDE.md example and only found generic templates, this is the one I wish I had found. New to the file itself? Start with the complete guide to CLAUDE.md and Claude Code's memory system, then come back here for the annotated real thing. And if you would rather start from a paste-ready file, I keep a free library of Claude Code templates with three CLAUDE.md starters in it.
TL;DR: A good
CLAUDE.mdis a short list of load-bearing instructions, not a docs dump. Keep it under about 200 lines, make every rule specific and non-obvious, put global habits in~/.claude/CLAUDE.mdand project facts in./CLAUDE.md, and use@importsto pull in long files instead of pasting them. The annotated config and the "why Claude ignores it" section below are the parts worth your time.
What is a CLAUDE.md file, really?
CLAUDE.md is the memory file Claude Code reads at the start of a session and keeps in context the whole time. Think of it as a standing instruction sheet: every prompt you send is effectively prefixed with it. Claude Code loads it automatically and delivers it as a user message right after its system prompt, so it carries real weight on every turn.
The single most useful mental model: CLAUDE.md is context, not enforcement. It strongly shapes behavior, but it is not a config file the runtime obeys mechanically. That distinction explains most of the frustration people have with it, and it is why the "make it stick" section later matters as much as the file itself.
The memory hierarchy: global, project, local, nested
Claude Code does not read one file. It loads several, from broad to specific, and the more specific ones layer on top:
| Scope | Location | Use it for |
|---|---|---|
| Enterprise / managed | OS-level managed path (set by an org) | Org-wide policy you do not control |
| User (global) | ~/.claude/CLAUDE.md | Your personal habits across every project |
| Project (shared) | ./CLAUDE.md or ./.claude/CLAUDE.md | Facts about this repo, committed for the team |
| Local (private) | ./CLAUDE.local.md | Your private notes for this repo, gitignored |
At launch Claude Code also walks up the directory tree and loads any CLAUDE.md it finds in parent folders, so a monorepo can have shared rules at the root and specific rules in a package. Files in subfolders are different: they load on demand, only when Claude actually reads a file in that subtree. Worth knowing, because people assume a nested CLAUDE.md is active from the first message when it is not.
A quick myth to kill while we are here: CLAUDE.local.md is not deprecated. The docs nudge you toward @imports instead, but the local scope still works and is still the right place for private, gitignored notes.
The global config, annotated
This is my ~/.claude/CLAUDE.md. It is deliberately short. These are habits I want in every project, regardless of language or stack:
# Global CLAUDE.md
## Up-to-date docs (Context7)
For non-trivial library or framework usage, use the Context7 MCP server to
fetch current, up-to-date documentation before writing code rather than
relying on training-data knowledge.
## Response format
End every response with a short "TL;DR:" line of 1-2 sentences summarizing
the reply.
## Parallel work
Distinguish two kinds of parallelism. Parallel tool calls (multiple
Read/Grep/Bash in one message) are cheap - do them whenever the calls are
independent. This should be the default. Spawning subagents is heavier - only
worth it when each agent has substantial, independent work. Do not manufacture
parallelism for small tasks, and do not spawn an agent to re-read files
already loaded in the current session.
## Verification
After making a series of code changes, verify the work before considering it
done - for example, run the relevant tests or checks rather than assuming it
works.
## End of session
At the end of any working session, remind me to save and back up my work -
for example, to commit and push any unpushed changes.
Here is why each one is in there, and what it prevents:
| Rule | What it actually prevents |
|---|---|
| Up-to-date docs | Confident code against an API that changed since the model's training cutoff - the single most common source of "looks right, does not run." |
| Response format | Having to re-read a long answer to find the outcome. The forced TL;DR makes every reply skimmable. |
| Parallel work | Two failure modes at once: serial tool calls that waste wall-clock time, and over-eager subagent spawning that burns your usage re-deriving context Claude already had. |
| Verification | The "it's fixed" claim that was never run. This rule turns "should work" into "I ran it, here is the output." |
| End of session | Losing an afternoon of work to an uncommitted, unpushed branch. Cheap insurance, paid once per session. |
Notice what is not in there. No "you are a senior engineer" preamble, no restating things Claude already knows, no project specifics. Every line is a habit that changes behavior and that Claude would not reliably do on its own. That is the bar a global rule has to clear.
The project config, and the @import trick
The global file is habits. The project CLAUDE.md is facts: how this repo is built, the traps specific to it, the commands that matter. The mistake here is pasting your whole architecture doc into it. Do not. Use an @import instead:
# CLAUDE.md
@AGENTS.md
## Writing style
- Never use em-dashes or en-dashes anywhere in this project. Use a regular
hyphen "-" instead. Applies to code, comments, UI copy, docs, and commits.
@AGENTS.md pulls that file's contents in at load time. A few things worth knowing about imports:
- They accept relative, absolute, and home-directory (
~/) paths. - They nest, up to a depth of about 4 hops, so an imported file can import others.
- The first time you import a file from outside the project, Claude Code asks for approval.
- Imports do not magically save context. The imported text still occupies the window. The win is organization and reuse (one source of truth shared across
CLAUDE.md,AGENTS.md, and your editor), not token savings.
The style rule above is a good example of a project fact that earns its place: it is specific, it is non-obvious, and there is a concrete alternative ("use a hyphen"), not a vague "write nicely."
Why does Claude ignore my CLAUDE.md?
This is the most common complaint, and it is usually one of four things. None of them is "Claude is broken."
- The rule is vague. "Write clean code" gives nothing to act on. "Functions over 40 lines must be split, and prefer early returns over nested conditionals" is followable. Specific, testable rules survive; aspirational ones get ignored.
- The file is too long. Adherence drops as the file grows. Past a couple hundred lines, every low-value rule you add dilutes the high-value ones. The fix is pruning, not more emphasis.
- Rules contradict each other. If two lines pull in opposite directions, Claude picks one and looks like it ignored the other. Read your file as a whole and remove the conflicts.
- Context got compacted. This is the sneaky one. The root project
CLAUDE.mdsurvives a/compact, but a long session can still push earlier instructions out of focus. If adherence drifts mid-session, run/memoryto confirm what is loaded, or just remind Claude of the rule in your next message.
Two anti-patterns make this worse, not better: writing rules in ALL CAPS with lots of exclamation points (it reads as noise, not priority), and the "add another rule" doom loop where every miss gets a new line. More rules is the problem, not the cure.
So when do I use a hook instead?
Because CLAUDE.md is context and not enforcement, some things do not belong in it at all. If a rule must happen every single time with zero drift - formatting on save, blocking a commit that fails lint, running a specific command after every edit - that is a job for a hook, not a memory file. The rule of thumb:
CLAUDE.md rules are strong suggestions. Hooks are enforcement. If "usually" is not good enough, reach for a hook.
How long should a CLAUDE.md be?
Short. Anthropic's own guidance is to target under about 200 lines, and the reason is mechanical: the file is in context on every turn, so a longer file both costs more tokens and reduces adherence to any single rule. My global file is well under 50 lines on purpose. If yours is growing, the right instinct is to delete the rules that are not pulling their weight, not to reorganize them.
Getting started
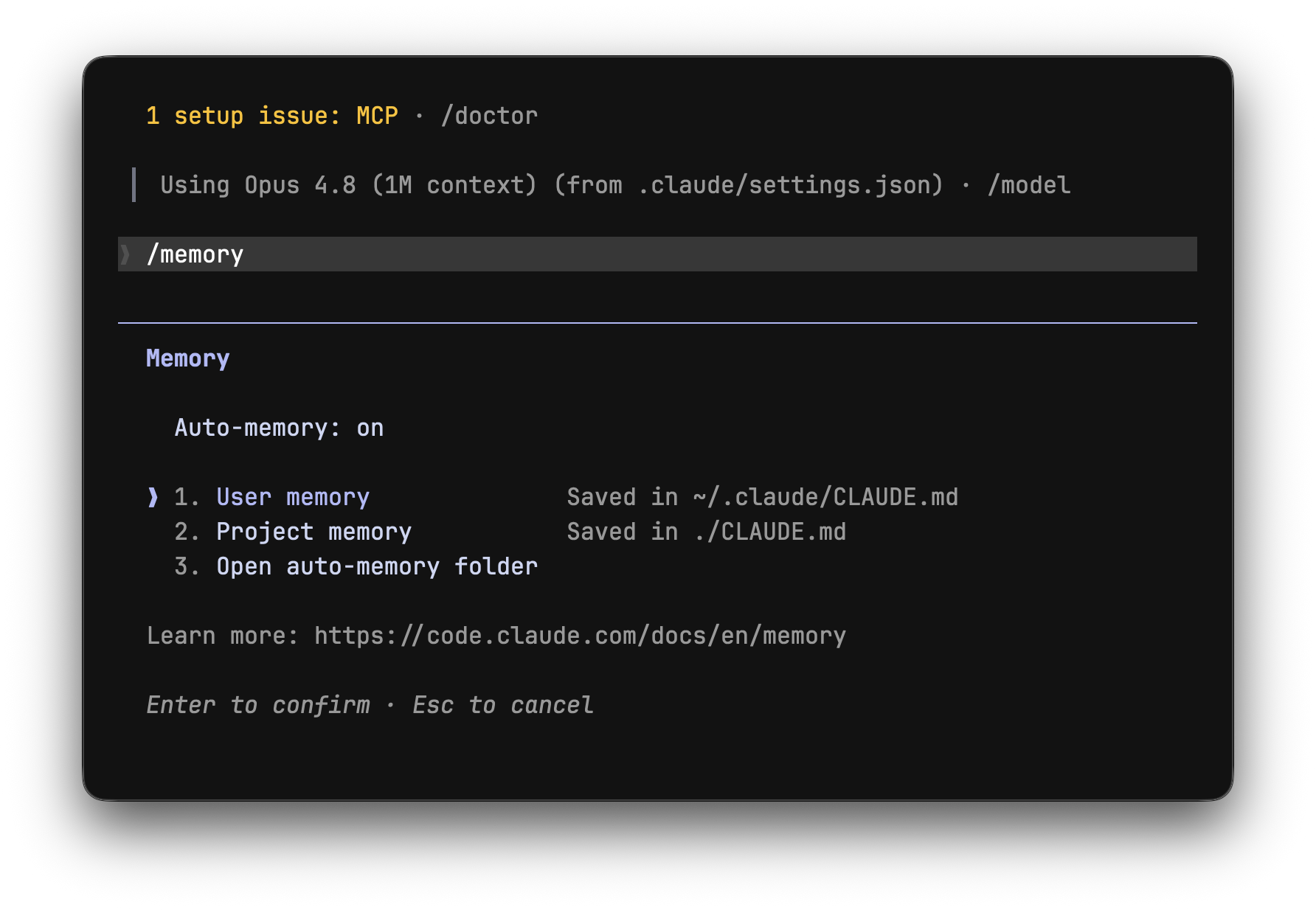
If you do not have a CLAUDE.md yet, the fastest on-ramp is the /init command inside Claude Code: it scans your repo and drafts a starter file (it will even read an existing AGENTS.md or editor rules). Then trim it hard - generated files are always too long. Use /memory any time to see exactly which files are loaded and open them for editing.
FAQ
What do I put in CLAUDE.md and what do I leave out? In: non-obvious habits and project facts that change behavior. Out: anything Claude can infer from the code, anything generic ("write good code"), and long reference docs (import those instead).
Global vs project vs local - which file do I use?
Personal habits that apply everywhere go in ~/.claude/CLAUDE.md. Facts about a specific repo, committed for the team, go in ./CLAUDE.md. Private notes you do not want committed go in ./CLAUDE.local.md.
Is there a quick shortcut to add a memory mid-session?
The cleanest current way is to just tell Claude "remember this" or run /memory to open and edit the file directly. (If you have seen references to a # shortcut, it is no longer documented - do not rely on it.)
Does CLAUDE.md get truncated if it is too long? No. The whole file loads regardless of length. The roughly 200-line figure is a quality guideline, not a hard cap - long files do not get cut, they just get followed less well.
A tuned CLAUDE.md is one piece of a setup that makes Claude Code reliable instead of hit-or-miss. The config above is mine, given away in full. If you would rather skip the trial-and-error, ClockedCode hands you the whole thing in one paste: a tuned global CLAUDE.md, a curated toolset, and the working habits behind them - the result of doing this the slow way so you do not have to.